|
The following is a letter to David Montgomery from Jake Jacobs, involving
several questions about variance reduction. I believe these questions and
David's answers are very illuminating. —Kit Woolsey
|
| Jake: |
I read with great interest David Montgomery's
article on Variance Reduction in the February 2000 issue. I am one of
those who sometimes uses "1995 methods" because I do not fully trust
variance reduction. Despite David's article (and a private conversation
we had last year, during which he gave me a private tutorial) I still
have questions. Perhaps David has the answers?
In your early chart, following game 3, you
show the results of 7 games. The known winning probability is 37.5%,
and your sample rollout gives a 50% probability, while your sample
variance reduced figure gives a 42% probability of winning. Two
questions here, then.
- When the bots report their
results, are they giving us the actual rollout figure (with their
variance reduced estimate of how accurate that figure might be), or the
variance reduced figure, without the actual rollout results?
- (and I understand this isn't really your department, David) Why not give us both?
| | David: |
- Every version of JellyFish and Snowie that I have used has given only the variance reduced results.
- I
think it would be better to make both results available. Having
multiple results for a single rollout makes both the implementation and
presentation a bit more complex, but I believe it's nevertheless
worthwhile.
| | Jake: |
In your 4th section, you discuss
the effect of bad evaluations, and show how, in the long run, they do
not matter. You mention that they may, if they are truly bad, increase
the variance, and so we'll need more trials to achieve accuracy.
- Do the bots ever realize that they may be using bad estimates?
- Shouldn't they then report this? For example, after 864 rollouts on
level 6 (Jelly), I am assured that we have achieved the equivalent of
"15,618" rollouts.
- Will I ever see 864 rollouts
reported as equivalent to "28" trials because of the bad estimates
used? (I have never seen such.)
- If the answer to E is no, may I assume that the bots will always claim greater accuracy
than the number of actual rollouts, regardless of whether that is, in
fact, true?
| | David: |
- The
bots don't "realize" anything, but they do report the standard
deviation or confidence interval of the rollout, which allows the user
to infer what is going on.
- The report
of the equivalent games is, in effect, a report on the quality of luck
estimates. When each game is worth many, then good evaluations were
used.
- It is unlikely that you will find something this severe,
but you can
get results where the equivalent games are fewer than the actual games.
With JellyFish version 2.0, a 72-game interactive (that is, manual but
variance reduced) rollout of this position
30
270
|

   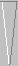 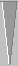    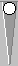 
 

|
White
Kauder paradox position
Blue |
had a higher standard deviation than you would
get using the actual game results. JellyFish 2.0 truly had no clue
about this kind of position. I no longer have the exact statistics, but
the increase in the standard deviation was modest. I have never seen
this kind of result in a "normal" position. If a program plays a
position well enough that you actually care about its rollout results,
you won't see this kind of problem.
- Assuming
the programmers are honest and competent, the equivalent games
indicated will reflect the actual statistical reliability of a rollout.
This is a judgment that applies to everything about a bot. My personal
belief is that the developers of Snowie and JellyFish are all honest
and highly competent individuals, but others have reached different
conclusions, and bugs have been found in every version of JellyFish and
Snowie.
| | Jake: |
In Inside Backgammon, Volume 8, Number 2,
Chuck Bower, discussing the correct plays at dmp gives results of 864
trial rollouts of the various openings. He says that on average JF
level 6 assured him these rollouts were the equivalent of over 18,000
trials each. Repeating his work, but with a random seed, JF gave me the
same estimate, but slightly different results. Last night I tried it
again, and happened this time to receive an estimate of 15,618 (the
figure I mentioned above). The specific problem I posed was: How to
play an opening 2-1 at dmp? Chuck's results show 13/11, 6/5 winning
49.7%, while splitting 24/23 wins 49.5%, hence slotting is preferable.
My own 864 rollouts last night had slotting winning 49.5%, but
splitting winning 50.1%. Now David mentions the importance of
noting the stds.
- What is a confidence interval? (The only thing I am confident of is that
I must have been daydreaming during the interval in which everyone else
was informed.) Slotting showed an ev of −.014, with an std of .011,
while splitting had an ev of +.007, and an std of .010. Is that not
exactly 2 std?
It happens, though, that we have a more extensive
rollout. In Harald Johanni's Backgammon Magazin Heft II/97 the
editor addresses the same problem. Harald used 1800 level 6 rollouts,
equivalent to 32,000, to learn that splitting won 50.1%, while slotting
won just 49.9%. Now that we have two long and marvelously "confident"
rollouts agreeing that splitting wins 50.1%, the issue is laid to rest,
no?
No! After my own 12,960 level 6 rollouts (equivalent to 32,000—Jelly is stuck on a number), slotting led 50.0% to 49.8%. The ev
difference was down to .006 (from .021) and the std was .003, so these
results, like last night's, were at exactly 2 std.
- Since my results last night, after 864 trials each way, were the
equivalent of 15,618 (each) and since I was within 2 std, I can ignore
the longer rollouts, and split with confidence, right David?
| | David: |
- Rather than
talking about confidence intervals in general, let me explain that term
as I was using it and as it will be of most use to GammOnLine readers.
Snowie 3 gives its rollout results as a 95% confidence interval, in a
form like +0.125 Ī 0.020. The Ī
0.020 is about twice (actually 1.96 times) what JellyFish would call
the standard deviation. The basic idea is that there is a very high
likelihood (about 95%) that the result you got (+0.125) is no more than
.020 away from the result you would get if you rolled the position out
forever.
- I suspect
you'll split (or slot) with confidence regardless of the rollouts and
what I say here, but let's try to untangle the many issues involved in
your question.
First, there is the general issue of what we
should make of rollout results which are close. The closer the
decision, the less reliant we should be on a computer rollout for
deciding what to do. Many factors bear on which play will be correct in
a particular situation, almost none of which are reflected in a
computer rollout. Fortunately, when plays are very close, it doesn't
matter a lot which play we choose.
Elaborating this idea, it's useful to keep in
mind the question that computer rollouts answer. They do not tell us
the correct decision. What they tell us is which decision is best
assuming both players from then on play exactly as the bot does. So
JellyFish level 6 rollouts tell us how to play when we are playing
cubeless money backgammon against JellyFish level 6.
This is not just an academic matter. Different
plays do better against different opponents. Against Expert Backgammon,
the correct 63 opening was 24/21 13/7. In Nackgammon, the correct 41
opening against JellyFish level 6 is 24/20 23/22. But this isn't the
correct 41 opening against Snowie nor probably against JellyFish level
7. So the results of close, cubeless money JellyFish level 6 rollouts
shouldn't have too much effect on how you play an opening 21.
Often the effect of a match score is more
important than considering who is playing (assuming two strong
players). The question you posed was how to play an opening 21 at DMP,
but answering that question based on rollouts played as though gammons
and backgammons counted is very suspect. The standard deviations and
equivalent games are also calculated assuming cubeless money play, so
they too are not directly applicable to your question.
Now let's turn to the data itself. First, you
have mixed different experiments, so its not surprising that the
results might differ. Chuck Bower's results were not based on rollouts
of an opening 21, but on rollouts of all the responses to an opening
21. If level 6 ever plays a second roll different from the play that
rolled out best, the two experiments are different. I don't have
Chuck's results, but in from my own I see that for a 43 response after
21 slotting 24/20* 24/21 did best at DMP, although level 6 plays 24/20*
13/10. I found several similar differences after 21 splitting.
From your letter it appears that JellyFish has a
bug in displaying the number of "equivalent games" for small standard
deviations. A 12960 game level 6 rollout of an opening position is
certainly equivalent to far more than 32000 games. I recommend ignoring
the equivalent games in both JellyFish and Snowie and concentrating on
the standard deviation or confidence interval, which relates much more
directly to what you need to know.
For large samples you can combine rollouts by
simply weighting each according to the number of trials. Combining your
data for slotting you have (864 × 49.5 + 1800 × 49.9 + 12960 ×
50.0)/(864 + 1800 + 12960) = 49.96%. For splitting you get 49.85%. Given
that the rollout data is only displayed to one decimal place, you
clearly can't have much confidence in this distinction.
To get the combined standard deviation is
trickier and I won't go into it here. The important principle is that
if you increase your sample size by a factor of F, you only get sqrt(F)
reduction in your standard deviation. To cut the standard deviation in
half, you have to quadruple your sample size.
You wrote: "Slotting showed an ev of −.014, with an std of .011,
while splitting had an ev of +.007, and an std of .010. Is that not
exactly 2 std?"
The standard deviation expresses
uncertainty about an equity by itself, but this isn't the right value
for comparisons between plays. Here, slotting should be thought of as
about −.014 Ī .022 (that is, its very likely
somewhere between −.036 and +.008) and splitting as +.007
Ī .020 (somewhere between −.013 and +.027).
The point is that there is uncertainty in both equities.
When standard deviations for two plays are similar, as they are
here and as they usually are when you do rollouts with the same number
of games, you can think of the standard deviation of the difference
between the two plays as about 1.4 times the average of the two standard
deviations. Here the difference between the two plays is +.007 − −.014
= .021. The approximate standard deviation of this difference is 1.4 ×
(.011 + .010)/2 = .015. So the difference here is about 1.4 standard
deviations, not two.
Let me summarize the points here:
- Think about the question a rollout answers and whether that will
answer your real question. Because of the match score, the way
JellyFish does rollouts, the closeness of the decision, and player and
situational factors, no matter how many trials you do here your real
question won't be answered.
- Assuming you think a rollout will answer your question, focus on
the standard deviation (or, in Snowie, the confidence interval) and
disregard the equivalent games. If you rolled a position out forever
the final result you would get is very likely to be within two standard
deviations of the result you have so far.
- When comparing checker plays, remember that there are two
uncertainties—one for each play. The standard deviation of the
difference in equity is roughly 1.4 times the two plays' standard
deviations averaged, assuming equal length rollouts.
| | Jake: |
One of the problems with Jelly level 6 is
that all results are cubeless. A big problem with Snowie has been its
speed. High-level rollouts are incredibly slow. Snowie 3 has "fixed"
this, by forcing (unless you know the secret to turning this off,
somebody?) the user to rely upon the settings of 20% and tiny for the
cubeful rollouts. (I am basing this upon the beta version. My upgrade
just arrived in the mail, and is not yet installed.)
These settings
save time by ignoring all candidate plays that fall below certain
thresholds. This is not a problem if the best move happens to be one of
Snowie's top choices on level 1, but with really tough problems Snowie
1, (or even Snowie 3) like a human, may be way off in its evaluation.
(Which is why my first response whenever someone tells me what "Jelly
said" or "Snowie said" is: "Was that after a rollout?")
- Assuming that Snowie 1's evaluation is way off, isn't it fair to assume
that the new cubeful rollouts, on level 2 or 3, but with 20%, tiny
settings, are really no better than those of level 1?
| | David: |
- This can't be answered simply either. Let's try to
look at the issues one by one.
Sampling (e.g., 20%).
Sampling is unlikely to make a big difference. The evaluations that
you get with 20% and 100% tend to be very close both in absolute equity
values and in play selections. 20% plays a little bit worse than 100%,
but not much. When 20% picks a worse play, it is almost always a play
that 100% thinks is a decent choice.
There is an interaction effect between sampling
and cubeful rollouts, because the cube turns and cubeful equities rely
on the absolute (as opposed to relative) values of the evaluations. But
I believe that sampled evaluations are almost always at roughly the
same levels as the 100% evaluations, so there is no significant
problems specific to cubeful rollouts. This is in marked contrast to
comparing 1-ply with 3-ply cubeful rollouts. Between 1 and 3-ply you
often have evaluations differing by .2 or more, and whether you do your
cube evaluations 1-ply or 3-ply will make a very big difference.
By the way, JellyFish level 7 also uses sampling; you just don't have
any option to adjust it or turn it off.
Search space (e.g., tiny).
For certain kinds of positions the search space will make a big
difference. For most of them, it does not, and in general you can use
the tiny search space with confidence. But you shouldn't think of the
smaller search spaces as restricting you to the 1-ply choice. The 1-ply
choices are screened according to your selected criteria, evaluated at
2-ply, screened again, evaluated at 3-ply, and then the best play
according to the 3-ply evaluation is made. With a perfect search space
you screen out all the stupid plays but none of the best plays. In
practice, you get pretty close to this with the tiny or small search
spaces for most positions.
Jellyfish, too, has a search space. Any bot that
plays with 3-ply in real-time must. In some positions you can have
thousands of legal moves, and it simply isn't worthwhile to evaluate
them all at 3-ply.
An important point is that it's not so important
that a rollout pick the best play each turn. What is important is that
it never pick really bad plays. Using the smaller search spaces Snowie
will occasionally miss the play it would have thought best with a huge
space, but only rarely will the play it selects be a bad play. Some
equity is probably given up on that turn, but equity is given up lots
of times even when Snowie plays at 100% huge.
There is very little interaction between the
search space and cubeful rollouts, because search space affects play
selection. If you change the search space the bot will sometimes play
differently—whether you are doing a cubeful or cubeless rollout.
Disregarding the changes in moves made, the changes in cube actions
will be very rare and insignificant.
I tend to use 20% sampling with tiny and small search spaces in my
rollouts, and 100%-huge when doing an analysis.
Comparing 1-ply Cubeful to 3-ply Cubeful
So if you do a 20% tiny cubeful rollout, is it the same as a 1-ply cubeful
rollout? No, not at all.
The basis for cubeful rollouts is still the
cubeless evaluation. If you do a cubeless evaluation on 1-ply, then 2,
and then 3, regardless of search space and sampling parameters, you
will often see big changes. A position can go from not good enough to a
drop, or conversely from too good to no double. If you use 3-ply to do
your cubeful rollout, you get the benefit of the better evaluations in
making these cube decisions.
Does this mean that the 3-ply result will be more
"accurate"? Let's go back to what a rollout tells us: it tells us the
equity assuming both players play exactly as the bot does with the
settings we've specified. Every rollout is perfectly accurate for this
question. As for perfect play, or in the finals tomorrow against a
strong player—well, generally 3-ply plays better than 1-ply, so most of
the time its rollouts should be closer to the theoretical truth. But
there are no guarantees.
In my article I assumed a correct implementation
of variance reduction. And everything else, for that matter. Once you
assume something might be wrong, anything can happen.
There is cause for caution with Snowie's rollouts.
Snowie 3 is an complicated program with lots of changes relative to
version 2. I've seen many bugs in the released version. Chuck Bower
posted a nice position on the GammOnLine bulletin board showing what
certainly looks like a bug in the variance reduction algorithm. A
position rolled out 1-ply by Chris Yep without truncation or variance
reduction reports an equivalent games greater than the actual games
rolled out, which makes no sense.
For the most part Oasya hasn't responded to bug
reports in public forums. I'm sympathetic to them because as far as I
know its just Olivier and Andrť and they have an awful lot of work
preparing the next version for us. But with so much complicated stuff
going on, and with so little of it adequately documented, it makes
sense to scrutinize Snowie rollouts carefully.
Thanks for your questions, Jake. I hope my answers are of some use.
Two other players contacted me with questions.
From Rob Maier I learned that it may seem that I assumed that the
evaluation of a position before the roll is equal to the
average of the evaluations after the roll.
But this isn't assumed—it's a direct result of the way
the before-roll evaluation is calculated. The before-roll
evaluation is the average of the continuations.
It may be useful to think of the before-roll evaluation
as a 2-ply or level 6 evaluation, while the after-roll
evaluations are 1-ply or level 5.
From Jeremy Bagai I learned that it may seem that I was
implying you get exactly the same equity whether you use
variance reduction or not. You get the same equity on
average; or equivalently, the same equity if you roll
a position out both ways forever. For equivalent
sample sizes, the distribution of rollout results is the same.
But because a rollout is a random process, two rollouts
are quite unlikely to give the exact same equity. This is
true whether or not variance reduction is used.
Thanks to Rob and Jeremy for pointing out these issues for
clarification.
David Montgomery
|
|